Kubernetes (K8s) is one of the best container orchestration platforms today, but it is also complex. Because Kubernetes aims to be a generalsolution for specific problems, it has many moving parts. Each of these parts must be understood and configured to meet yourunique requirements.
Further, all the moving parts create a challenge: your DevOps team must have sufficient expertise in Kubernetes to reliably and efficiently navigate the configuration and management complexities. Here, we’ll take a closer look at these Kubernetes challenges to help you better understand and prepare for them. We cover the skill set requirements for managing Kubernetes in a separate article.
Why is Kubernetes complex?
Complexities with K8s primarily arise because different applications with different requirements are all running on the same cluster. Let’s take the example of a company that does payment processing. They will have systems such as :
- A payment gateway system
- A website where users can submit their credit card details for payments
- A notifications system to notify users about successful or failed payments
- Applications that interface with bank accounts to transfer money
The technical requirements for each of these systems will be different. For example, the payment gateway might need to have the ability to scale to millions of credit card transaction requests each holiday season, but bank account interfaces might not need to scale as much. Additionally, to allow users to load the website from anywhere in the world quickly, there may be a requirement for the site to be globally distributed.
All these requirements need to be explicitly configured in Kubernetes. This need for explicit configuration of significantly different systems brings about complexity in managing the underlying server resources.
Specific drivers of Kubernetes complexity and operational challenges
To help drive the point home, let’s look at some specific K8s challenges that can arise in production environments. In the table below, we provide a high-level overview of Kubernetes challenges. In the subsequent sections, we’ll take a closer look at each of these challenges.
| Challenge | Details |
|---|---|
| Meeting isolation standards | Isolation of applications on the same server is vital for security. |
| Internal networking challenges | The latency between services needs to be accounted for in large clusters. |
| Limited visibility into resource utilization | In large clusters with many applications and services running, it is difficult to know what level of resources systems are consuming. |
| Optimizing resource usage | As the cluster grows in size, cost management and resource optimization become more critical and more complex. |
| Deployment failovers and downtime mitigation | Large-scale application rollouts must have fail-safes to avoid downtime risk. |
| Reduced visibility into data flows | As a cluster grows in size and across regions, maintaining visibility into data flows becomes increasingly complex. |
| Patch management | Applying K8s security patches and updates at scale without interrupting service or impacting performance is an operational challenge. |
| Access management and tenant isolation | For large clusters, isolation between different teams or customers using the cluster must be configured. |
| On-prem challenges | Running clusters on your own data center infrastructure adds additional management complexities, including: avoiding network partitions, and upgrading servers |
Meeting isolation standards
In our examples, we’ll continue to use our hypothetical payment processing company as a reference. With that in mind, let’s begin with “meeting isolation standards.” An isolation standard can mean ensuring different services cannot communicate with restricted containers.
For example, our website containers cannot communicate with the containers running the bank transfers system to secure the banking interfaces. To achieve this isolation, we can apply Kubernetes policies that prohibit communication between select containers.
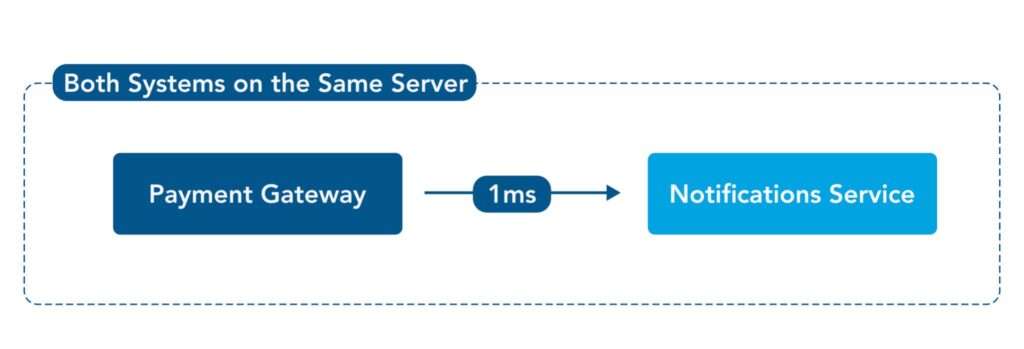
Internal networking challenges
Our example payment gateway will need to use the notifications service to send regular payment notifications. If K8s locates these services on servers that are not physically close to each other, the added latency will drastically slow down the app over millions of requests. These types of Kubernetes networking challenges can be mitigated by co-locating services on the same server using node-affinities and node-anti-affinity policies.
Optimizing resources usage
As clusters grow in size, without active monitoring and many policies to co-locate services on servers, you can end up in a situation with hundreds of servers running at lower capacity than they can handle. This underutilization means higher costs.
To address this challenge, you must actively commit to regular resource optimization. Of course, the visibility into resource utilization mentioned above is a prerequisite for success. Kubernetes scaling policies can mitigate some underutilization risk, but a deeper evaluation of how to optimize usage at regular intervals remains essential for cost and resource management at scale.
Deployment failovers and downtime mitigation
High availability, fault tolerance, and the ability to minimize downtime is a must for most large-scale production applications. For example, an update to the payment gateway to accept AMEX cards should be able to roll back quickly (and across your entire cluster) if the deployment ends up not working in production due to a misconfiguration.
Reduced visibility into data flows
As your cloud or on-prem K8s cluster grows in size, it becomes difficult to trace how the data flows between endpoints. For example, you would want the payment notifications system instances in New York City to interface with the payment gateway instances in the same city instead of the payment gateway instances in Los Angeles. The challenge is achieving complete network visibility to determine precisely how data is flowing in production.
To improve K8s network visibility, you need robust monitoring solutions for networking and alerting systems to notify your team if something isn’t performing as desired.
Patch management
Patching hundreds of servers with all the latest security updates and versions of Kubernetes is difficult as cluster size grows. Having good policies on your applications such as PodDisruptionBudget and following best practices for server updates like draining and cordoning can help keep servers updated without downtime.
Access management and tenant isolation
If different teams or customers use your application, you need to enforce policies that keep them isolated. RBAC (role-based access control) and other isolation mechanisms like namespace isolation and networking policies are tools to ensure these challenges are addressed.
Since identity management (IAM) is not supported out of the box by Kubernetes, your team will have to roll out a custom solution (particularly in on-prem deployments where public cloudIAM services can’t be leveraged) to make sure access control works as intended.
On-prem challenges
Avoiding Network Partitions
Network partition is a situation where one part of the network is unable to communicate with another segment. These involuntary disruptions can occur without warning due to misconfigurations. As a result, part of your cluster may suddenly disappear because of a network failure and cause significant disruption. It is important to have monitoring configured to detect such scenarios and processes to resolve these issues quickly.
Smooth Upgrades to Servers
When updating hundreds of servers, your team must ensure failover processes are in place to mitigate downtime caused by failures. For example, sufficient additional servers should be present for failover in case updates do not complete successfully.
Summary
The issues covered in this article are some of the biggest challenges to keep in mind with large Kubernetes cluster deployments. While best practices can help, nothing beats experience. That’s why we recommend having engineers on your DevOps team with prior experience managing mission-critical applications on K8s clusters. We describe the required skill sets for managing large K8s clusters in a separate article in this guide.
You like our article?
You like our article?
Follow our monthly hybrid cloud digest on LinkedIn to receive more free educational content like this.
Consolidated IT Operations for Hybrid Cloud
Learn MoreA single platform for on-premises and multi-cloud environments
Automated event correlation powered by machine learning
Visual workflow builder for automated problem resolution