OpsRamp Platform Updates
SUMMER 2021
Spring 2021
Fall 2020
OpsRamp Summer 2021 Release
The Summer 2021 Release helps modern IT operators deliver outstanding customer experiences with intelligent event management, powerful hybrid infrastructure monitoring, and enhanced user experience.
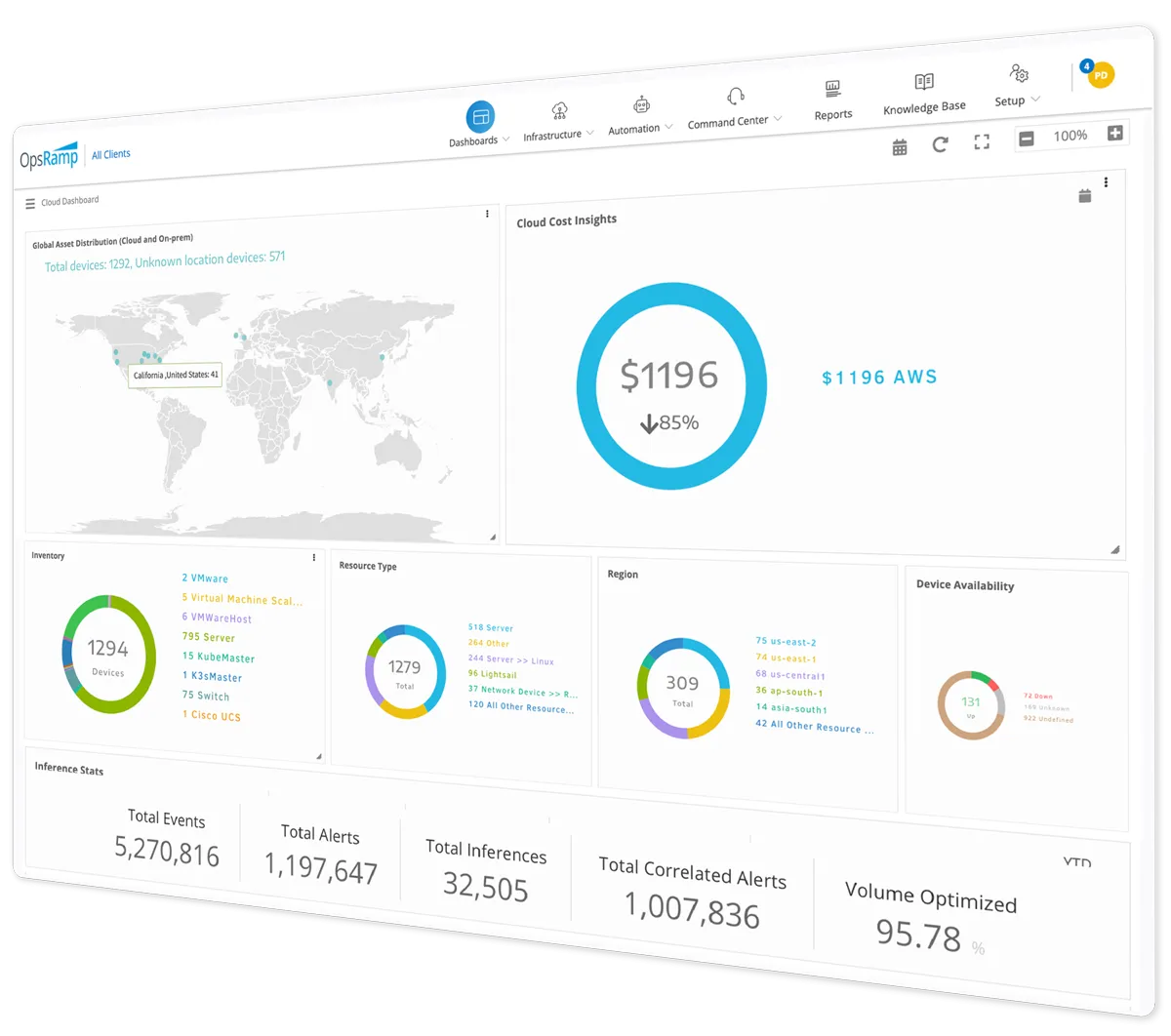
Alert Enrichment. The sheer volume, velocity, and variety of operational data such as metrics, logs, traces, and events can quickly overwhelm the most seasoned IT teams. If technology operators have to respond quickly to critical incidents, they need more actionable insights from their alert notifications. Alert enrichment policies accelerate problem resolution by augmenting the ‘problem area’ field in an alert description. Enriched alerts can be used for faster event correlation and drive timely incident response with alert metadata information.
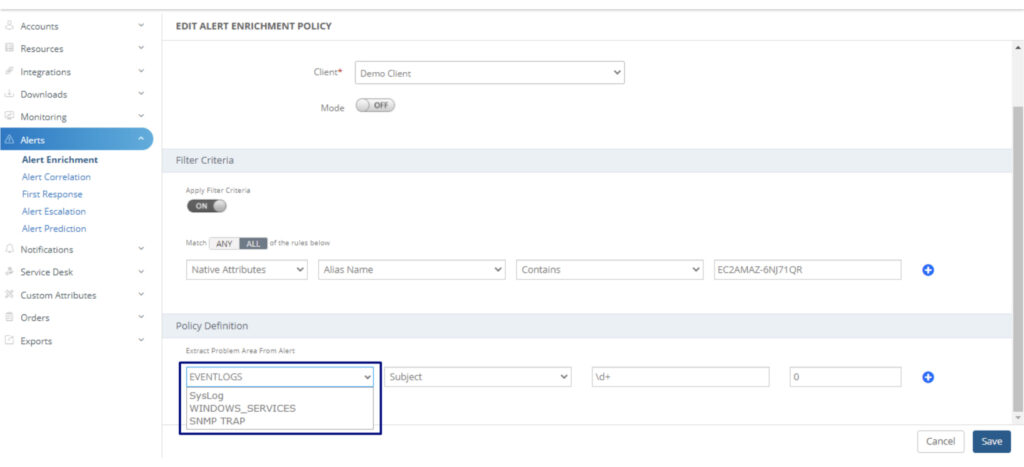
Predictive Alerting. Predictive alerting improves enterprise reliability and performance by detecting leading indicators of possible systemic failure. Alert prediction policies analyze historical time series data for seasonality patterns to predict and prevent business-impacting IT outages. Predictive alerts can also be linked to automation workflows to drive proactive responses for impending service disruptions.
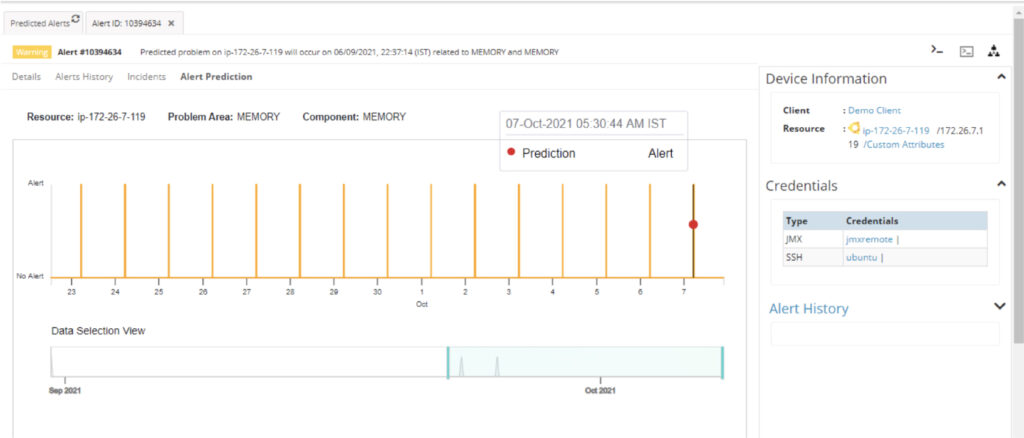
Cloud Monitoring. While Alibaba Cloud has a strong presence in the Chinese and Asia Pacific market, it has grown into a global cloud powerhouse with more than 9 percent worldwide market share. Cloud operators can now monitor the performance and availability of core Alibaba Cloud services such as ECS instances, Auto Scaling, RDS, Load Balancer, EMR, and VPC.
Datacenter Monitoring. While public cloud spending is growing much faster than datacenter investments, organizations still run their mission-critical workloads on-premises for a number of reasons. System administrators can now monitor the performance of their enterprise workloads running on Hitachi VSP OpsCenter, NAS and HCI, VMware vSAN, NSX-T and NSX-V, Dell EMC PowerScale, PowerStore and PowerMax, and Poly Trio, VVX/CCX and Group using OpsRamp.
User Experience. Incident managers can quickly respond to alerts and incidents with OpsRamp’s new mobile application that supports both Android and iOS devices. Operators can reduce blue-light fatigue with dark mode user interface that offers better ergonomic support and improves readability for incident troubleshooting.
OpsRamp Spring 2021 Release
The Spring 2021 Release delivers innovative capabilities for hybrid cloud operations with self-service onboarding, metrics observability, powerful dashboarding, centralized alerting, and cloud and hyperconverged infrastructure monitoring.
Rapid Onboarding. Cloud infrastructure adoption is showing no signs of slowing down in 2021, with global enterprises expected to spend more than $300 billion on public cloud services. OpsRamp enables faster migration to multi-cloud and cloud native infrastructure with its newly introduced auto-monitoring capabilities. Automated monitoring abstracts the heavy lifting needed to discover a cloud resource, configure and clone monitoring templates, and adjust alert thresholds. Once cloud operations teams provide access details for their cloud environments, auto-monitoring discovers, monitors, and builds out-of-the-box dashboards for popular cloud services without any manual configuration.
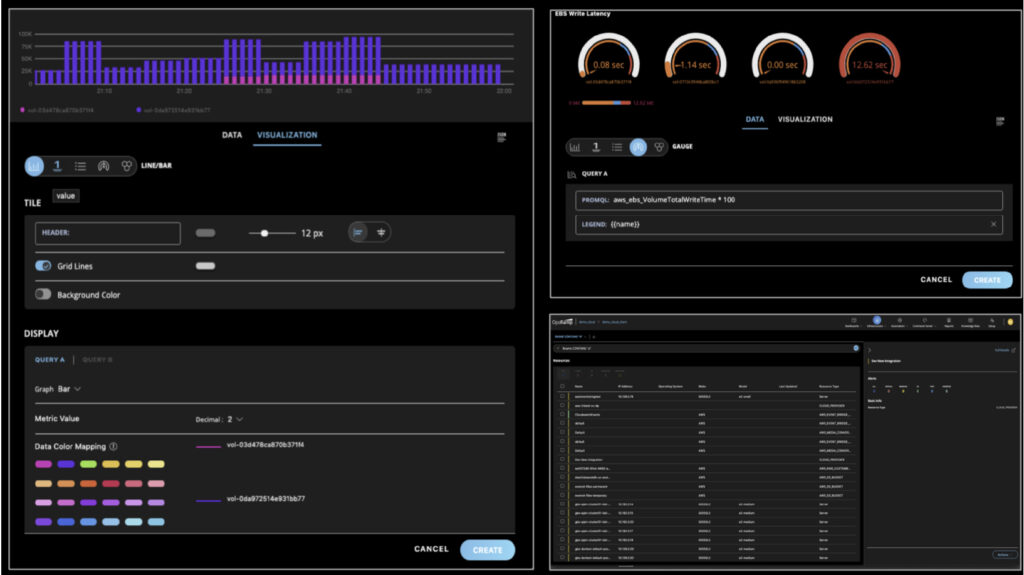
Data-Driven Insights for Hybrid IT Management. Cloud infrastructure management requires operators to shift their focus from getting the data out (instrumentation) to information visualization and alerting workflows. OpsRamp’s powerful new dashboards are built on Prometheus Query Language (PromQL), which is the de-facto expression language for extracting relevant insights from a time-series database. Our new dashboards offer powerful customization capabilities for effective hybrid monitoring and can be either imported or shared across different users.
Cloud Native Metrics Observability. The three most popular projects in the Cloud Native Computing Foundation (CNCF) ecosystem are Kubernetes, Prometheus, and Helm. OpsRamp can now directly consume Prometheus metrics which can then be used for building dashboards or sending alerts. OpsRamp offers a volume-based pricing model for ingesting Prometheus metrics which are stored at 12-month intervals. CloudOps teams can also cut down on Prometheus data sent to OpsRamp so that they are not spending on superfluous metrics. OpsRamp also supports native event ingestion for Prometheus Alertmanager so that operators can use the AIOps and workflow automation capabilities to respond to critical issues.
Flexible and Centralized Alerting.Cloud operators can now create alert definitions that spell out warning and critical thresholds for a metric. This allows operators to take a metric, filter by key tags in the metrics, configure a threshold, and then build routing policies to make sure an alert goes to the right person. Alert definition models provide flexibility in configuring threshold settings and act as a logical layer that sits above the metric data.
Cloud and Hyperconverged Infrastructure Monitoring.OpsRamp now offers additional monitoring coverage for Microsoft Azure services such as Blob Storage, Table Storage, File Storage, BatchAI Workspaces, BlockChain, Databox Edge, and Kusto Clusters. The platform can also discover, monitor, and ingest events for Cisco HyperFlex components as well as discover and monitor physical components of Dell EMC VxRail appliances.
OpsRamp Fall 2020 Release
The Fall 2020 Release delivers innovative capabilities for Discovery & Monitoring with the new Onboarding Wizard, curated dashboards, and greater support for cloud native and multi-cloud services. Remediation & Automation updates include human interaction for automated workflows, workflow monitoring, and multi-instance loops.
Discovery & Monitoring
In response to the global pandemic, a recent Gartner forecast finds spending on public cloud services will exceed $300 billion in 2021. OpsRamp offers comprehensive support for 150+ public cloud services across Amazon Web Services (AWS), Microsoft Azure, and Google Cloud. The platform also integrates with container orchestration tools such as Kubernetes, OpenShift, K3s, and Containerd as well as managed cloud Kubernetes environments. The Fall 2020 Release makes it easy for IT operations teams to discover, monitor, alert, and optimize their cloud infrastructure with minimal effort.
Hybrid Cloud Onboarding Guide. The new hybrid cloud onboarding guide offers step-by-step instructions on how to integrate your cloud and cloud native services within OpsRamp. The Onboarding Wizard is a guided walkthrough that quickly discovers and monitors multi-cloud environments in four simple steps:
- Step 1 – Select the different cloud and cloud native integrations that you wish to install across AWS, Azure, and Google Cloud.
- Step 2 – To onboard your cloud account, provide account credentials, select region, specify IAM role/user, and enter the account number, access key, and security key.
- Step 3 – Filter the cloud and cloud native resources that you wish to onboard using tags, resource types, or pre-defined defaults.
- Step 4 – Configure your discovery schedules, decide if you want to stream CloudWatch alarms, CloudTrail events, or AWS events, and click finish.
After onboarding your cloud account, you can immediately access curated dashboards to analyze the health and status of your cloud and cloud native environments.
Curated Dashboards.The powerful new dashboarding model uses the PromQL query builder for delivering granular metric insights for deeper analysis and better visualizations. IT teams can either build curated dashboards from scratch or customize specific tiles in an existing dashboard. Operators can also create a central dashboard repository for their business units or re-use dashboards for shared IT services.
Container and Multi-Cloud Monitoring. OpsRamp can now automatically detect and monitor business applications hosted on containerized infrastructure. IT admins can see which applications are running inside container clusters, instrument container runtimes with OpsRamp agents, and gain quick visibility into app performance using dashboards. OpsRamp can auto-detect and monitor more than 25 popular apps such as Apache Kafka, Apache Cassandra, MongoDB, and MySQL. We have also expanded public cloud coverage to include AWS ECS, Azure Functions, Azure Hyperscale, and Azure SQL Managed Instance.
Remediation & Automation
By 2024, research firm IDC expects that 50% of employees will leverage personal bots to prioritize critical work and outsource repetitive activities. The Fall 2020 Release ensures resilient and reliable hybrid infrastructure with intelligent automation capabilities.
Human Interaction for Automated Workflows. IT operations teams can now add human interaction tasks for an automation workflow. If a workflow touches a critical piece of your production infrastructure, you can request approvals before a remediation action can take place on a device. This ensures the right actions get taken to resolve an issue with the right amount of human oversight and accountability.
Workflow Monitoring. IT teams can gain complete visibility into their automation workflows and associated tasks with workflow monitoring. Operators can understand which particular step of a workflow is running, which process is waiting for approval, track any errors that might have occurred, and receive a full audit trail of their workflow.
Multi-Instance Loops. Some operational processes require processing on multiple resources at the same time for service, script, platform, and API-level tasks. When an admin needs to run a task on two different resources at the same time, they can use multi-instance loops to complete sequential tasks in a single step.